16 Auth in Enterprise
Imagine you’re suddenly responsible for managing all the software access in an enterprise. You’ve got dozens of people joining, leaving, and changing roles each week – and there could be hundreds of data sources and services they need to do their jobs. You can’t just give everyone access to everything. You might be getting a headache just imagining the situation.
Luckily, if you work in an enterprise, you won’t have to worry about this task. Instead, managing the process of giving people access to the services they need, called auth, is one of the prime responsibilities of the IT/Admin group.
While the good news is that a professional is taking care of auth, the bad news is that you’ll have to figure out how to work with the organization’s corporate auth to log in to your data science workbench and use data sources. Additionally, if you’re advocating for a data science environment at your organization, you’ll probably be given IT/Admin requirements related to auth.
This chapter will help you understand how IT/Admins think about auth and the technologies they can use. By the time you’ve finished, you should be able to communicate effectively with whoever manages auth at your organization.
This chapter will help you understand a mental model for auth and the available technologies. If you’re curious about the technical operation of these technologies, there’s more detail on each in Appendix A.
Gentle introduction to auth
Consider all of the services in an enterprise that require auth: email, databases, servers, social media accounts, HR systems, and more. Now, imagine yourself as the person who’s in charge of managing all that auth.
I find it helpful to think of each service as a room in a building. Your job is to give everyone access to the rooms they need and only the rooms they need.
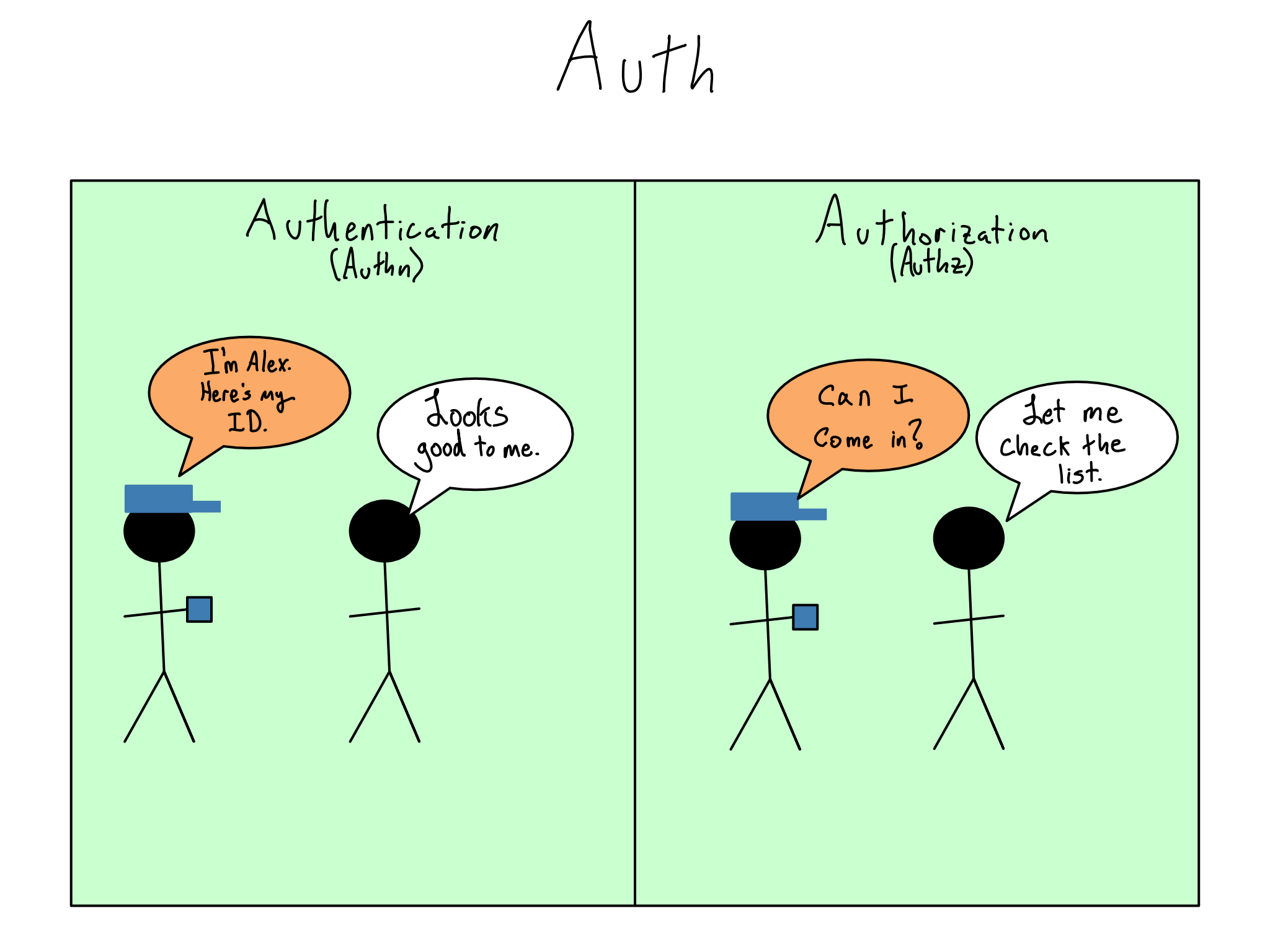
First, you need to know who a person is when they try to enter a room. To do that, you’ll need to issue and verify credentials in the authentication (authn) process. The most common computer credentials are a username and password. While they are common, passwords are quite insecure because they can be stolen or cracked and many are unwisely re-used.1 More secure alternatives are on the rise and include passkeys, biometrics like fingerprints and facial identification, multi-factor codes, push notifications on your phone, and ID cards.
But just knowing that someone has valid credentials is insufficient. Remember, not every person gets to access every room. You’ll also need a way to check their permissions, which is the binary choice of whether that person can enter that room. The permissions checking process is called authorization (authz). The combination of authn and authz comprise auth.
Many organizations start simply. They add services one at a time and allow each to use built-in functionality to issue service-specific usernames and passwords to users. This would be similar to posting a guard at each room’s door to create a unique credential for each user.
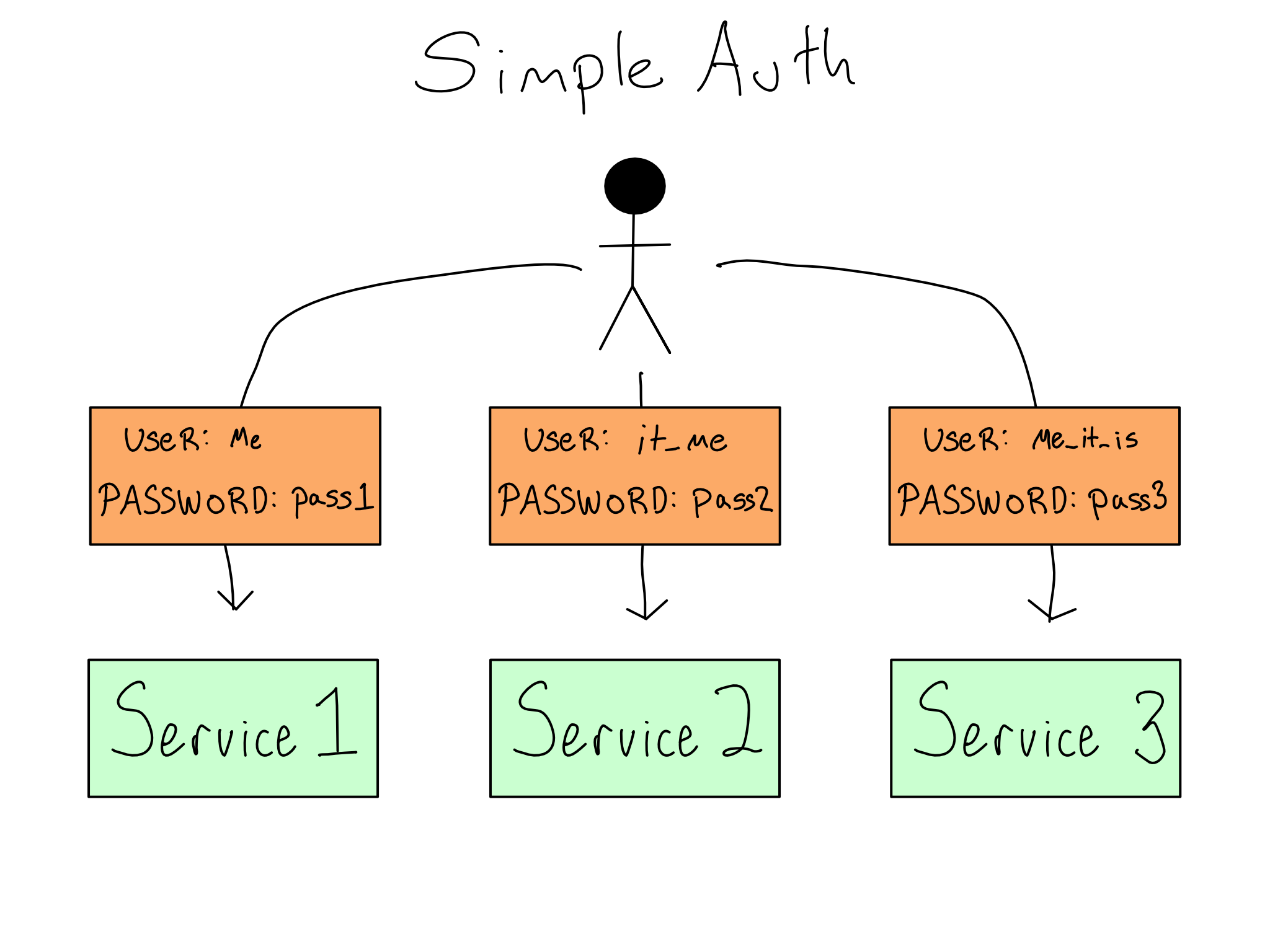
This quickly becomes a mess for everyone. It’s bad for users because they either need to keep many credentials straight or re-use the same ones, which is insecure. And as an IT/Admin, adding, removing, or changing permissions is cumbersome, because each system has to be changed individually.
Centralizing user management with LDAP/AD
In the mid-1990s, an open protocol called LDAP (Lightweight Directory Access Protocol, pronounced ell-dapp) became popular. LDAP allows services to collect usernames and passwords and send them to a central LDAP database for verification. The LDAP server sends back information on the user, often including their username and groups, which the service can use to authorize the user. Microsoft implemented LDAP as a piece of software called Active Directory (AD) that became so synonymous with LDAP that the technology is often called LDAP/AD.
Switching to LDAP/AD is like changing the door-guarding process so the guard will radio in the user’s credentials and you’ll radio back if those credentials are valid. This is a vast improvement for users, as life is easier with only one set of credentials. Now, all the rooms are using a similar level of security. If credentials are compromised, then it’s easy to swap them out.
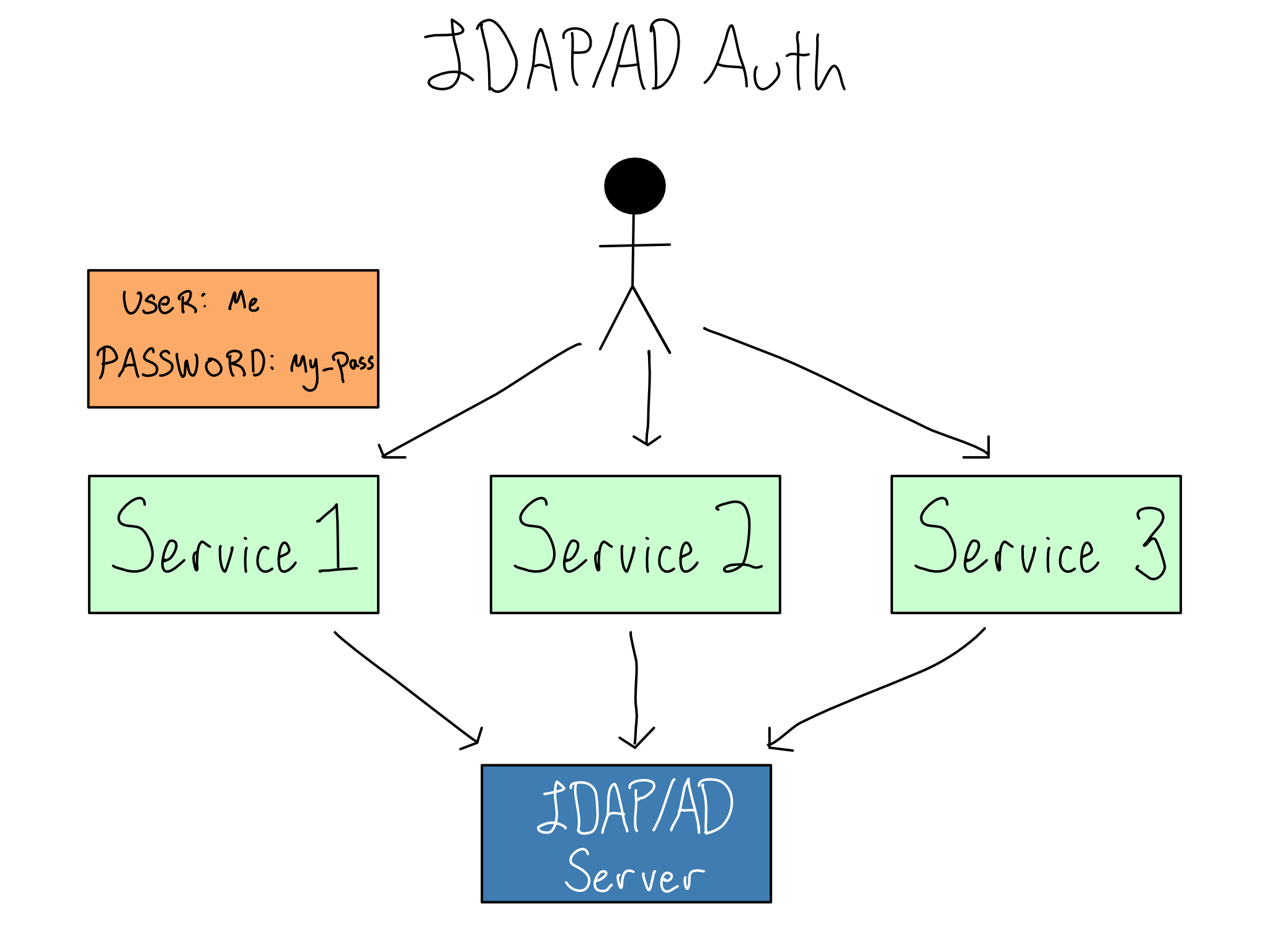
LDAP/AD also provides a straightforward way to create Linux users with a home directory, so it’s often used in data science workbench contexts that have that requirement.
LDAP/AD is being phased out in many organizations. LDAP/AD predates the rise of the cloud and SaaS services. It is usually used on-prem and has limited features relative to SSO providers.
Additionally, LDAP/AD introduces a potential security risk, as the service has to collect and handle the user credentials when it sends them to the LDAP server. It also means it’s usually impossible to incorporate now-common requirements like multi-factor authentication (MFA). Many organizations are getting rid of their LDAP/AD implementations and are adopting a smoother user and admin experience with cloud-friendly technologies.
It’s worth noting that LDAP/AD isn’t really an auth technology at all. It’s a type of database that happens to be particularly well suited to managing users in an organization. So even as many organizations are switching to more modern systems, they may be wrappers around user data stored in an existing LDAP/AD system.
The rise of Single Sign On
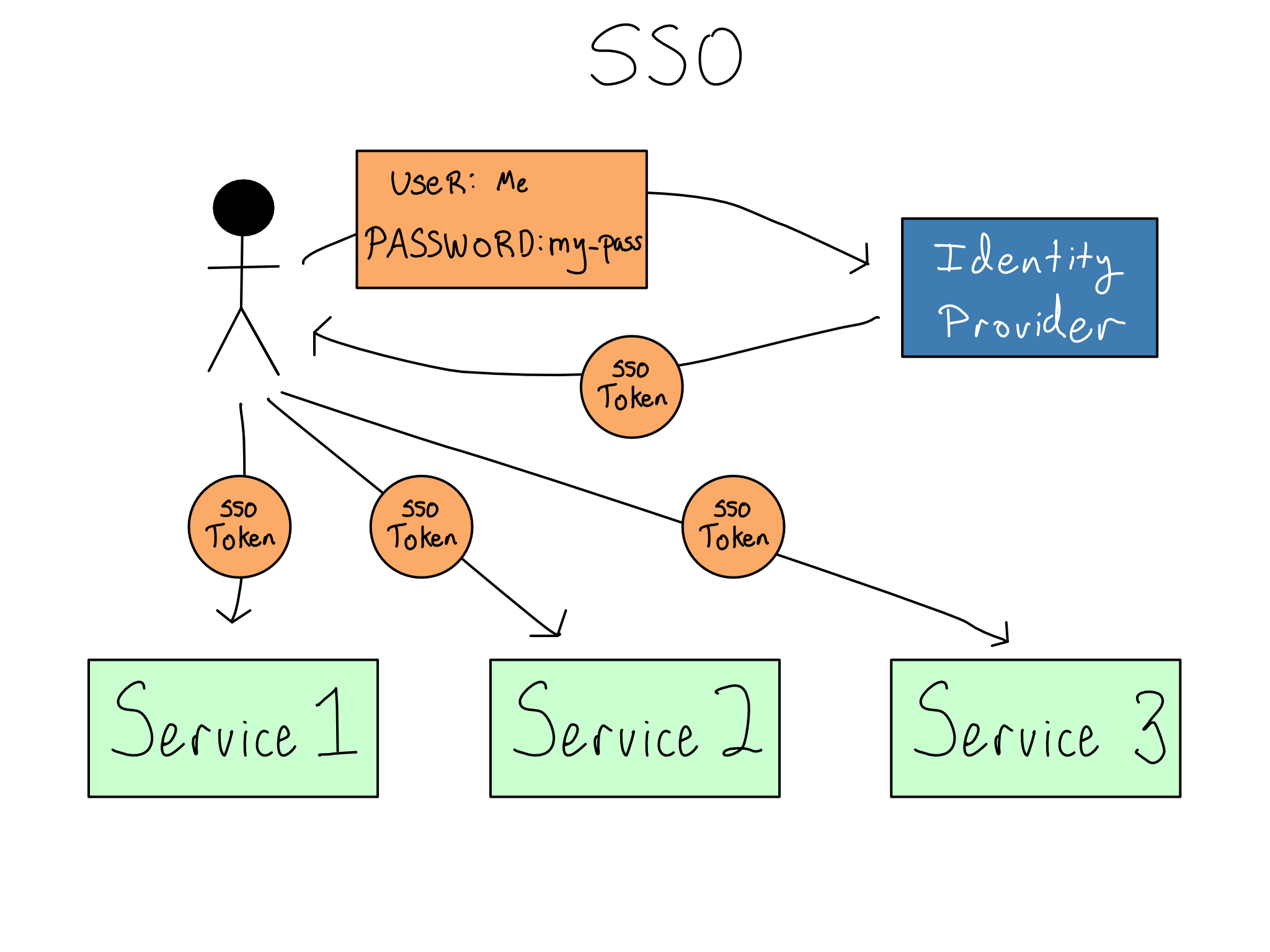
Single Sign On (SSO) is when you log in once to a standalone identity provider at the start of your workday. The identity provider gives you a secure SSO token that is responsible for granting access to various services you might use.2
If you’re thinking of services like rooms in a building, the SSO token is like issuing users an access pass when they enter the building. Then, when they go to enter a room, they can swipe the access pass and gain entry if they’re allowed.
As an auth admin, SSO is great because you only have to manage authentication and authorization in one place – at the identity provider. Additionally, implementing sophisticated credentials, like MFA, is only dependent on support from the identity provider, not the individual services. As a user, the the acquisition and management of SSO tokens are mostly hidden, so you get a pleasant “it just works” experience as you access different services throughout the day. For many organizations, SSO is a requirement for any new service.
The term SSO is somewhat ill defined. It usually means the experience described here, but sometimes it just means the centralized user and credential management in an LDAP/AD system.
It’s worth being clear – SSO is not a technology. It is a user and admin experience that is accomplished through technologies like SAML (Security Assertion Markup Language) or OIDC/OAuth (Open Identity Connect/OAuth2.0).3. Most organizations implement SSO through integration with a standalone identity provider like Okta, OneLogin, Ping, or Microsoft Entra ID.4
Over the last few years, there’s been an accelerating transition from on-prem systems like LDAP/AD to cloud-friendly SSO systems and the enhanced security they enable. In particular, the use of non-password credentials like passkeys and the use of OAuth to do sophisticated authorization management inside enterprises are quickly moving from being cutting-edge to being standard practices.
Connecting to data sources
Whether you’re working directly on a data science workbench or deploying a project to a deployment platform, you’re almost certainly connecting to a database, storage bucket, or data API along the way.
It used to be the case that most data sources had simple username and password auth, so you could authenticate by just passing those credentials along to the data source, preferably via environment variables (see Chapter 3). This is still the easiest way to connect to data sources.
Organizations are increasingly turning to modern technologies, like OAuth and IAM, to secure access to data sources, including databases, APIs, and cloud services. Sometimes, you’ll have to manually navigate the token exchange process in your Python or R code. For example, you’ve likely acquired and dispatched an OAuth token to access a Google Sheet or a modern data API.
Increasingly, IT/Admins want users to have the experience of logging in and automatically accessing data sources. This situation is sometimes termed passthrough auth or identity federation. This is a great user experience and is highly secure because there are never any credentials in the data science environment, only secure cryptographic tokens.
However, this experience is more complicated than it appears. From what we’ve discussed so far, it seems like you could use the SSO token that got you into the data science environment to access the data source. But it doesn’t work like that. Instead, accessing each service requires its own token that can’t be used for a different service for security reasons. So, “passthrough” is a misnomer, and a much more complicated token exchange is required.
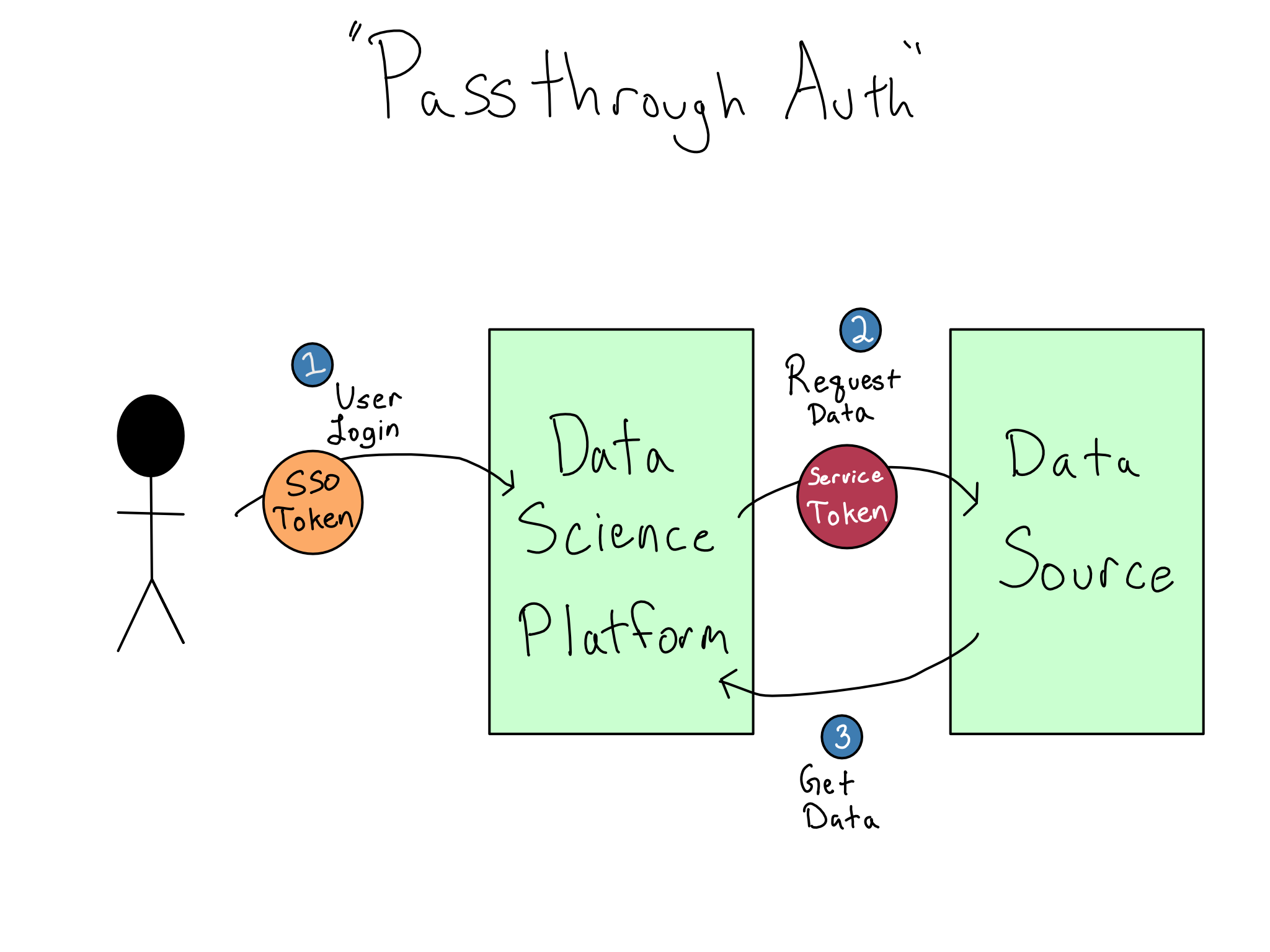
OAuth and IAM are quickly becoming industry standards for accessing data sources, but automated handoffs for every combination of SSO technology, data science platform, and service token aren’t fully implemented. I expect broader adoption in the next few years. For now, you’ll need to talk to your IT/Admin team about whether there’s an integration to access a data source seamlessly when you log in or if you’ll have to continue using a username and password for a little longer.
Another technology you may encounter when accessing data sources is an old, but very secure, technology called Kerberos that uses a Kerberos Ticket to connect to databases and file shares. Kerberos is most often used in on-prem Windows environments with LDAP/AD.
Managing permissions
Irrespective of the technology used, your organization will have policies about managing permissions that you must incorporate or adopt.
There are meaningful differences in how LDAP, SAML, and OAuth communicate to services about permissions. That’s a level of detail beyond this chapter – more in Appendix A if you’re interested.
If your organization has a policy that you’re going to need to be able to enforce inside the data science environment, it’s most likely a Role Based Access Control (RBAC) policy. In RBAC, permissions are assigned to an abstraction called a role. Users and groups are then given roles depending on their needs.
For example, there might be a manager role that should have access to specific permissions in the HR software. This role would be applied to anyone in the data-science-manager group as well as the data-engineering-manager group.
There are a few issues with RBAC. Most importantly, if there are many idiosyncratic permissions, creating tons of special roles is often simpler than figuring out how to harmonize them into a system.
Many organizations don’t need the complexity and power of RBAC. They often use simple Access Control Lists (ACLs) of who can access each service.5 ACLs have the advantage of being conceptually simple, but maintaining individual lists for each service is a lot of work with many services and users.
Some organizations are moving toward even more granular techniques than RBAC and are adopting Attribute Based Access Control (ABAC). In ABAC, permissions are granted based on an interaction of user-level and object-level attributes and a rules engine.
For example, you can imagine three distinct attributes a user could have: data-science, data-engineer, and manager. You could create a rules engine that provides access to different resources based on the combinations of these attributes and attributes of the resources like, dev and prod.
Relative to RBAC, ABAC allows for more granular permissions, but it’s a much bigger lift to configure initially. You’ve already encountered an ABAC system in the AWS IAM system. You were probably completely befuddled if you tried to configure anything in IAM. You can thank the power and complexity of ABAC.
Comprehension questions
- What is the difference between authentication and authorization?
- What are some advantages of token-based auth? Why are most organizations adopting it? Are there any drawbacks?
- For each of the following, is it a username + password method or a token method: PAM, LDAP, Kerberos, SAML, ODIC/OAuth?
- What are some different ways to manage permissions? What are the advantages and drawbacks of each?
If you’re reading this book, you’re probably already aware. But you really should use a password manager to make sure your passwords are strong and that you don’t re-use them.↩︎
I’m using the term token colloquially. The actual name for this token depends on the underlying technology and may be called a token, ticket, or assertion.↩︎
OIDC is an authentication standard based on the much broader OAuth authorization standard. As a user, you’ll never know the difference. There is a technology called Kerberos that some organizations use to accomplish SSO with LDAP/AD, though this is rare.↩︎
Until recently, Microsoft Entra ID was called Azure Active Directory, which confusingly was for SSO, not Active Directory. That’s probably why they changed the name.↩︎
Standard Linux permissions (POSIX permissions) that were discussed in Chapter 9 are a special case of ACLs. ACLs allow setting individual-level permissions for any number of users and groups, as opposed to the one owner, one group, and everyone else permissions set for POSIX. Linux distros now have support for ACLs on top of the standard POSIX permissions.↩︎