Enterprise-Grade Data Science
Most data scientists don’t have the discretion to stand up and use servers whenever they want. Many organizations, and almost all large ones, operate with security, process, and scale requirements that require professional IT/Admins to manage their servers.
I will refer to these larger, more mature organizations as enterprises. If you work at an enterprise and need a server, your IT/Admins can be great partners or infuriating gatekeepers.
Having professional IT/Admins on your side is great when the collaboration works well. You get to focus on doing data science, while the IT/Admin creates a great environment where you can work. But, even in the best cases, you’re working with people on a different team, with a different understanding of the work, and with different concerns and priorities.
This part of the book will help you to understand the IT/Admins’ point of view in an enterprise. By the end of the subsequent few chapters, I hope you know why they don’t just let you set up servers, that you understand their tools, and that you are prepared to articulate what you need from them.
Creating a DevOps culture
As a data scientist, your primary concern about your data science environment is its usefulness. You want the latest versions of Python or R, abundant access to packages, and data at your fingertips.
Great IT/Admin teams also care about the system’s usefulness to users (that’s you), but it’s usually a distant third to their primary concerns of security and stability. And that focus benefits you. Minute-to-minute, you may be primarily focused on getting data science work done, but an insecure or unstable data science platform is not useful to anyone.
There’s a reason why these concerns primarily arise in an enterprise context. If you’re a small team of three data scientists sitting next to each other, accidentally crashing your workbench server is a chance for a coffee break and an opportunity to learn something new about how servers work.
But if you’re working on an enterprise-wide data science workbench supported by a central IT/Admin function, it’s infuriating if someone three teams over can disturb your work. And you don’t want to work in an environment where you must consider every action’s security implications.
Balancing security, stability, and usefulness is always about tradeoffs. The only way to be 100% sure that private data will never leak is never to give anyone access at all. Organizations that do DevOps right embrace this tension and are constantly figuring out the proper stance for the whole organization.
It is an unfortunate truth that many IT/Admin teams don’t act as partners. They act as gatekeepers to the resources you need to do your job, which can be incredibly frustrating. While it’s unfair, you stand to lose more if they don’t give you the access you need, so you’ll have to learn what matters to those teams, communicate what matters to you, and reach acceptable organizational outcomes.
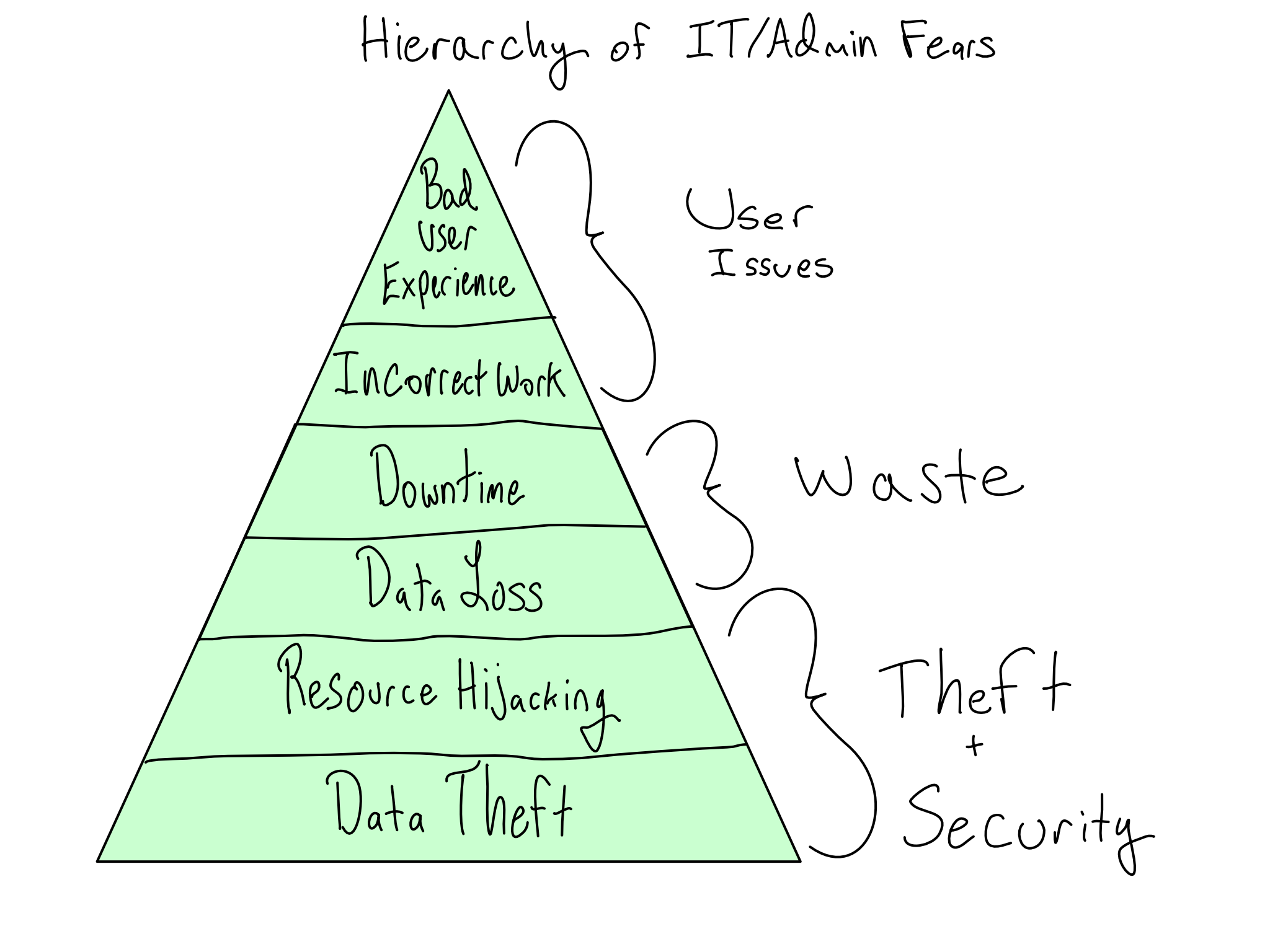
A hierarchy of IT/Admin concerns
The primary concerns of IT/Admins are security and stability. A secure and stable system gives valid users access to the systems they need to get work done and withholds access from people who shouldn’t have it. If you understand and communicate with IT/Admins about the risks they perceive, you can generate buy-in by taking their concerns seriously.
The worst outcome for a supposedly secure data science platform would be an unauthorized person gaining access and stealing data. In the most extreme form, this is someone entirely outside the organization (outsider threat). But it also could be someone inside the organization who is disgruntled or seeking personal gain (insider threat). And even if data isn’t stolen, it’s bad if someone hijacks your computational resources for nefarious ends like crypto-mining or virtual DDOS attacks on Turkish banks.1
Somewhat less concerning, but still the stuff of IT/Admin nightmares is platform instability that results in the erasure of important data, called data loss. And even if data isn’t permanently lost, instability that results in lost time for platform users is also bad.
IT/Admins may have some stake in ensuring that the environment doesn’t include error-ridden software that results in incorrect work. And last, way down the list, is that users don’t have a bad experience using the environment.
Enterprise tools and techniques
Conceptually, enterprise IT/Admins always try to implement security in layers. This means an application or server has multiple kinds of protection, making an accidental or intentional breach less likely.
At every layer, sophisticated organizations try to implement the principle of least privilege. The idea is to give people the permissions needed to complete their work – and no more. For example, you might want root access on your data science workbench, but you are not getting it if you work in an enterprise because you shouldn’t need it in your day-to-day work.
There is no one-size-fits-all (or even most) way to implement these ideas. Your organization should choose a solution that balances the value of universal availability of information versus the risk of breach or disclosure.
One big question any enterprise IT/Admin faces when creating a data science environment is whether to build or buy one. Some IT/Admin organizations prefer to build data science platforms straight from open-source tools, like JupyterHub and RStudio Server. Conversely, some want to buy seats on a SaaS solution.
I am admittedly biased on this question, as I work for a company that sells software to create data science platforms. But in my experience, only enterprises with extraordinarily competent IT/Admin teams can be better off building.
I have seen many organizations decline to buy Posit’s Pro Products in favor of attempting to build a platform. Many come back 6 or 12 months later, having discovered that DIY-ing an 80% solution is easy, but creating a fully enterprise-ready data science environment from open-source components is hard.
Networking is the first line of defense for keeping bad actors out of private systems. If the network is secure, it’s hard for bad actors to infiltrate and hard for insiders to accidentally or intentionally exfiltrate valuable data. That’s why Chapter 15 discusses how enterprises approach networking to create highly secure environments.
If you work in a small organization, everyone likely has access to nearly everything. For larger or more security-conscious organizations, it is a higher priority that people have access to the systems they need – and only the systems they need. Sophisticated approaches are required to manage the access of many users to many systems and complex rules that govern who has access to what. In Chapter 16, you’ll learn the basics of how enterprises think about providing a way to log in to different systems and how you can make use of those tools in a data science context.
Once IT/Admins feel that the platform is secure, their concerns turn to ensuring it has sufficient horsepower to support all the users that need it and implementing ongoing upgrades and changes with minimal interruption to users. Chapter 17 discusses how enterprises manage computational resources to ensure stability, especially when a lot are required.
Lastly, there are your concerns as a data scientist. In particular, using open-source R and Python packages can be complicated in an enterprise context. That’s why Chapter 18 is all about the difficulties I’ve observed for organizations using open-source packages and the solutions I’ve seen work for those environments.
By the time you’ve finished these chapters, I hope you’ll be able to articulate precisely the needs of your enterprise data science environment and be a great partner to IT/Admin when issues, tension, or problems arise.
(No) labs in this part
As this part of the book is about developing mental models and language to collaborate with IT/Admins, there are no labs in this part of the book. There are, however, a lot of pictures and comprehension questions to ensure you’ve grasped the material.
Yes, both things I’ve actually seen happen.↩︎